

@4/21/2021
이거 그냥 예전에 keras랑 씨름하면서 쓴거라 멀쩡한 내용인지 가늠이 안되어서 shorts로 분류함
Day1

단순한 예시
# 2. 모델 구성하기
model1 = tf.keras.models.Sequential([
tf.keras.layers.Dense(
units=노드갯수,
input_dim=입력 노드갯수
activation=활성화함수,
),
])
Python
복사
모델 만들기 , Dense가 출력층이라면 노드갯수가 출력되는 데이터 모양이 된다
# 3. 모델 학습과정 설정하기
model1.compile(optimizer='adam',
loss='mean_squared_logarithmic_error',
metrics=['accuracy'])
Python
복사
# 4. 모델 학습시키기
result = model1.fit(X,y)
Python
복사
모델 학습하기
제대로 된 사용

# 1. 데이터셋 생성하기
...
(x_train, y_train), (x_test, y_test) = ...
# 2. 모델 구성하기
model = Sequential()
model.add(Dense(units=64, input_dim=28*28, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
# 3. 모델 학습과정 설정하기
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 4. 모델 학습시키기
hist = model.fit(x_train, y_train, epochs=5, batch_size=32)
# 5. 학습과정 살펴보기
print('## training loss and acc ##')
print(hist.history['loss'])
print(hist.history['acc'])
# 6. 모델 평가하기
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=32)
print('## evaluation loss and_metrics ##')
print(loss_and_metrics)
# 7. 모델 사용하기
xhat = x_test[0:1]
yhat = model.predict(xhat)
print('## yhat ##')
print(yhat)
Python
복사
Day2



fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Python
복사
데이터 전처리
패션 MNIST데이터를 사용한다.
image(2차원 배열)은 label(0~9인 정수)와
대응된다. label은 오른쪽에 나와있는 것 처럼
분류되어있다.
image 배열의 값들은 0~255인 픽셀 밝기이다.
train셋에는 6만개의 사진(배열)들이 있다
train_images.shape = ( 6만 , 28, 28 )
len(train_labels) = 6만
마찬가지로 test셋 또한 같은 형태로
1만개의 데이터가 있다.
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Python
복사
인덱싱으로 값을 찾을 수 있게 List를 만들어둔다
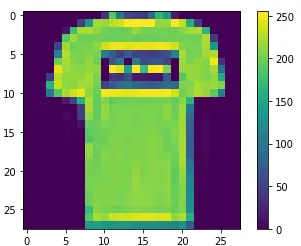
2차원 배열을 plt으로 시각화 한 것이다.
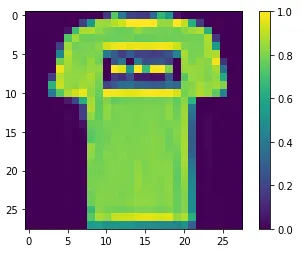
train_images = train_images / 255.0
test_images = test_images / 255.0
Python
복사
[ 0 ~ 255 ] → [ 0 ~ 1 ] || 왼쪽 이미지 → 오른쪽 이미지
모델 구성
레이어 설정
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
Python
복사
•
이 네트워크의 첫 번째 층인 tf.keras.layers.Flatten은
2차원 배열(28 x 28 픽셀)의 이미지 포맷을 28 * 28 = 784 픽셀의 1차원 배열로 변환합니다.
이 층은 이미지에 있는 픽셀의 행을 펼쳐서 일렬로 늘립니다.
이 층에는 학습되는 가중치가 없고 데이터를 변환하기만 합니다.
•
두번째 층은 128개의 노드(또는 뉴런)를 가집니다.
Dense층들은 밀집 연결(densely-connected)층이라고 부릅니다
•
마지막 층은 10개의 노드의 소프트맥스(softmax) 층입니다.
이 층은 10개의 확률을 반환하고 반환된 값의 전체 합은 1입니다.
즉, 각 노드는 현재 이미지가 10개 클래스 중 하나에 속할 확률을 출력합니다.
컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Python
복사
•
옵티마이저(Optimizer)
데이터와 손실 함수를 바탕으로 모델의 업데이트 방법을 결정합니다.


•
손실 함수(Loss function)
훈련 하는 동안 모델의 오차를 측정합니다. 모델의 학습이 올바른 방향으로 향하도록 이 함수를 최소화해야 합니다.
•
지표(Metrics) — ( 모니터링용 손실함수 )
훈련 단계와 테스트 단계를 모니터링하기 위해 사용합니다. 다음 예에서는 올바르게 분류된 이미지의 비율인 정확도를 사용합니다.

훈련
model.fit(train_images, train_labels, epochs=5)
Python
복사
훈련 데이터를 모델에 주입합니다 , 모델이 학습합니다.
Epoch(에포크)는 가중치를 업데이트하는 횟수를 말합니다.
Batch(배치)는 가중치를 한번 업데이트시킬 때 사용되는 샘플들의 묶음을 의미합니다.
샘플들이 차례대로 들어가는데 Batch만큼 흐른 뒤 가중치가 업데이트되는것!
평가
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\n테스트 정확도:', test_acc)
Python
복사
테스트 데이터를 사용해서 정확도를 확인합니다.
훈련셋과 테스트셋의 정확도차이는 overfitting때문입니다. 이것을 확인합니다.
evaluate 메서드는 해당 데이터에서 모델의 정확도를 알려줍니다!
모델 사용하기
predictions = model.predict(test_images)
Python
복사
predict 메서드는 입력값을 받은 뒤 계산된 데이터를 출력합니다.
결과 확인하기
predictions[0]
-------OUTPUT-------
array([1.7927578e-04, 9.7309680e-07, 2.0041271e-05, 1.7340941e-06,
5.4875236e-06, 7.3947711e-03, 2.7816868e-04, 1.0243144e-01,
1.9015789e-04, 8.8949794e-01], dtype=float32)
Python
복사
np.argmax(predictions[0]) → 9 , class_name[9] → 'Ankle boot'
모델은 해당 이미지가 앵클 부츠일 확률이 가장 높다고 말합니다.
학습된 모델에 이미지 하나만 넣어보기
img = (np.expand_dims(test_images[0],0))
img = [test_images[0]] # 위와 같은 내용
Python
복사
predictions_single = model.predict(img)
np.argmax(predictions_single[0])
----OUTPUT----
9
Python
복사
아몰랑 자연어처리
word2vec 사랑해요
Note1
•
전처리 방법들
◦
내장 메서드를 사용한 전처리 (lower, replace, ...)
◦
정규 표현식(Regular expression, Regex)
◦
불용어(Stop words) 처리
◦
통계적 트리밍(Trimming)
◦
어간 추출(Stemming) 혹은 표제어 추출(Lemmatization)
•
벡터화(Vectorize)
◦
등장 횟수 기반: 단어가 등장하는 횟수를 기반으로 벡터화
▪
Bag-of-Words (CounterVectorizer)
▪
TF-IDF (TfidfVectorizer)
◦
분포 기반: 타겟 단어 주변에 있는 단어를 기반으로 벡터화
▪
Word2Vec
▪
GloVe
▪
fastText

NLP에서 전처리를 하는 이유
전체 말뭉치에 존재하는 단어의 종류가 데이터셋의 Feature, 즉 차원이 된다
이 Feature를 줄여주어야 한다

등장 횟수 기반으로 백터화하였다
이렇게 피처가 쓸데없이 많은걸 희소한(Sparse) 행렬 이라고 표현한다
위와같이 단어가 문장에 나타난 갯수를 토큰화 해주게 되는데
아래와 같이 불필요한 피처 갯수가 너무 많다
["student","scientist?","alphabet","that","to","she","student."]
Python
복사
전처리를 안한 상태에서 'student' 와 'student.'가 다른 피처로 취급되고 있다.
import re
def lower_and_regex(sentence):
sentence = sentence.lower()
sentence = re.sub(r"[^a-z ]", "", sentence)
return sentence
Python
복사
모두 소문자로 만들고 정규식으로 소문자 알파벳만 남겨두는 전처리를 통해서 차원을 줄일 수 있다
( 함수 적용 후 저 희소한 행렬은 16차원으로 줄어든다 )
Note2
인코딩: 텍스트를 숫자로 바꾸어주는것
ex: 안녕 반가워 → 안녕=1 , 반가워=2
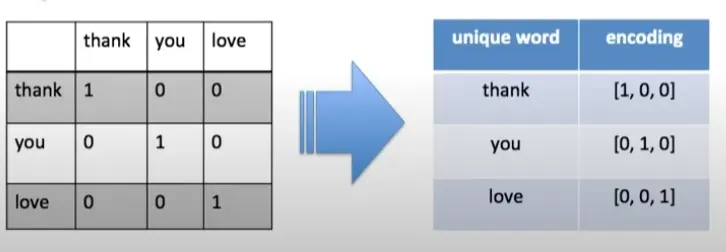
One Hot Encoding
임베딩: 유사도를 표현할 수 있으며 OneHotEncoding 보다 차원이 적다
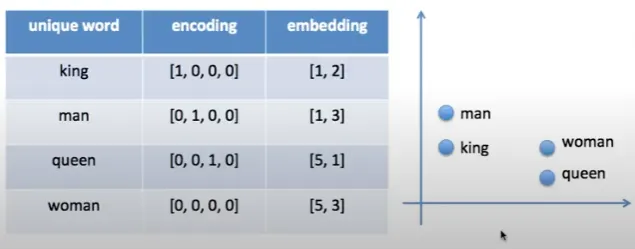
임베딩으로 표현된 좌표의 거리로 유사도를 볼 수 있다
Word2Vec은 임베딩 방법중 하나이다. 말그대로 비슷한 위치에 있는 것으로 유사도를 알 수 있다.
Word2Vec방법중 하나로 skipgram이 있다...
